眼窩前頭皮質

眼窩前頭皮質の機能は、認知地図の構成である。それはステート空間においてステートを表現することで可能となる。それぞれのステートは観測可能な情報(感覚、行動)と、観測不能な情報(記憶、推論から導いた情報で、しばしば価値情報を伴う)を統合することで表現される。
眼窩前頭皮質、前頭眼窩野、前頭前野眼窩部(がんかぜんとうひしつ、ぜんとうがんかや、ぜんとうぜんやがんかぶ 英: Orbitofrontal cortex, OFC orbital Prefrontal Cortex, oPFC)は、脳の前頭前野の腹側表面[1]で、意思決定に重要な役割を果たす[2]。
目次
1 機能
1.1 ヒトにおける眼窩前頭皮質の役割
1.1.1 ヒトにおける眼窩前頭皮質の損傷
1.2 健常者に対する脳機能イメージング研究
1.3 ラットにおける眼窩前頭皮質の機能抑制実験から分かった機能局在
1.3.1 内側眼窩野
1.3.2 外側眼窩野
1.3.3 眼窩前頭皮質の一部もしくは全体の破壊・機能抑制によって遂行障害が出る課題一覧
1.4 サルにおける断線実験
1.4.1 断線(disconnection)
1.4.1.1 眼窩前頭皮質ー扁桃体(OFC-AMY)
1.4.1.2 眼窩前頭皮質ー鼻皮質(OFC-RCX)
2 構造
2.1 霊長類の眼窩前頭皮質の解剖・組織
2.2 ラットの眼窩前頭皮質の解剖・組織
3 研究
3.1 マウスの眼窩前頭皮質の神経細胞の軸索投射
3.1.1 眼窩前頭皮質→線条体投射[22]
4 ステート表現
4.1 ステート空間理論
4.2 三段階課題ステート実験
4.3 消去学習
4.4 眼窩前頭皮質のステート表現には海馬の出力が必要である
5 逆転学習とステート表現
5.1 眼窩前頭皮質と基底外側扁桃体
6 モデルベースの推論
6.1 モデルベースの推論に基づく行動課題
6.1.1 ①脱報酬価値課題(Reinforcer Devaluation)
6.1.2 ②感覚事前調整(Sensory Preconditioning)
6.1.3 ③報酬内容の変更による脱阻止(Unblocking by reward identity change)[18]
6.1.4 ④PIT(Pavlovian-Instrumental Transfer)
6.1.5 ⑤マルコフの2ステップ課題ラット版
6.1.6 ⑥過剰期待
6.2 海馬-眼窩前頭皮質-腹側被蓋野(Hip-OFC-VTA)によるモデルベースの推論
6.2.1 背側海馬(dorsal Hippocampus:dH)
6.2.2 眼窩前頭皮質(Orbitofrontal Cortex:OFC)
6.2.3 腹側被蓋野(ventral tegmental area:VTA)
7 価値情報の表現
7.1 報酬価値のシグナルとその意思決定における役割
7.2 眼窩前頭皮質の神経細胞の電気活動
7.3 眼窩前頭皮質の神経細胞が表現している情報一覧
8 ラットにおける眼窩前頭皮質と他領野との相互作用
8.1 海馬と眼窩前頭皮質(Hip-OFC)連関[36]
8.2 基底外側扁桃体-眼窩前頭皮質(BLA-OFC)連関[37]
8.3 眼窩前頭皮質と腹側線条体(OFC-VS)連関[38]
8.4 眼窩前頭皮質-腹側被蓋野(OFC-VTA)連関[39]
8.5 眼窩前頭皮質-二次運動野[41]
9 潜在的原因表現
10 患者に対する神経心理学的研究
11 著名な眼窩前頭皮質の研究者
12 関連項目
13 出典
14 外部リンク
機能
眼窩前頭皮質の多彩な役割を要約すると、意思決定の基盤となる認知地図を構成することである。認知地図の構成は観測可能な情報と観測不能な情報を統合して推論を行い、ステートと呼ばれるある種の状態を表現することによって可能となる[1]。観測可能な情報は、現在の感覚入力や自らの行動である。観測不能な情報は、直接的な経験やモデルベースの推論によって得られる情報である。部分的に観測可能な環境情報にはしばしば、価値情報が伴う。[3]
ヒトにおける眼窩前頭皮質の役割
眼窩前頭皮質はヒトの脳の中でも最も理解が進んでいない領域である。しかし、この領域は、感覚情報や記憶情報の統合、強化子 (reinforcer) の感情価 (affective value) の表現、意思決定や期待に関連しているという考えが提唱されている[4]。特に、ヒトの眼窩前頭皮質は報酬と罰に対する感受性に関連した行動計画を制御していると考えられている[5]。このことはヒトや非ヒト霊長類、げっ歯類の研究から支持されている。
ヒトの眼窩前頭皮質では主観的な快楽性の経験を仲介する役割を持っているという説も存在する [4]。
ヒトにおける眼窩前頭皮質の損傷
後天性脳損傷 (ABI : Acquired Brain Injury) による眼窩前頭皮質の損傷は、一般的にある種の脱抑制行動を引き起こす。例えば、過度に悪態をつく、性欲過多、社会的対話の欠如、賭博への衝動、アルコール、煙草、薬物の摂取過多、共感能力の欠如などが起きる。ある種類の前頭側頭型認知症 (frontotemporal dementia) 患者の脱抑制行動は眼窩前頭皮質の変性が原因であるとされている[6]。眼窩前頭皮質に損傷を受けた患者は、衝動的な決断や、経済感覚の欠如などの症状が起きる。
健常者に対する脳機能イメージング研究
ヒトの眼窩前頭皮質の活動を画像化するために機能的核磁気共鳴画像法 (fMRI) を用いることは、この領域が副鼻腔に近いことにより困難なものとなる。副鼻腔には空気が詰まっており、高磁場でのエコープラナー撮像法 (EPI) の使用は信号の欠損や、画像の歪み、磁化率アーティファクトなどが発生しやすくなるためである。そのため、眼窩前頭皮質から質のよい信号を得るには特別な注意が必要とされ、様々な手法が用いられている。(例えば、高静磁場における自動シミング[7]など)
発表された脳機能イメージング研究によると、報酬価値、予測された報酬価値、さらには食べ物や他の強化子に対する主観的な喜びの度合いまでもが、眼窩前頭皮質で表現されている。大規模な脳機能イメージング研究のメタアナリシスにより、眼窩前頭皮質の内側部は強化子の報酬価値のモニタリング、学習、記憶に関係し、外側部は罰の評価に関係することで、現在行っている行動に変化を引き起こすことが示されている[8]。 同様に、前後方向に強化子の複雑性、抽象性が表現されていて、味覚などの複雑性の低い強化子よりも、金銭の収支のようなより複雑で抽象的な強化子に対して、眼窩前頭皮質のより前方が活動する。
ラットにおける眼窩前頭皮質の機能抑制実験から分かった機能局在

Reversal learning:逆転学習 Strategy and set shifting:戦略変更 Unobservable/uncertain outcome encoding:観測不能な不確実な成果のコード Delay discounting:時間割引 Outcome prediction and confidence:成果の予測と自信 Reinforcer devaluation and PIT:脱報酬価値課題とPIT Reward magnitude and identity discrimination:報酬の規模と同一性の識別
眼窩前頭皮質の破壊・機能抑制の結果、眼窩前頭皮質の因果的機能についてさまざまなことが分かった。ここではラットでの実験の結果を中心に説明する。眼窩前頭皮質をさらに内側、腹側、外側、背外側、外側-島の5領域に分類し、それぞれの領域がどのような役割を果たしているかを右図にまとめる。[9]
内側眼窩野
ラットの眼窩前頭皮質研究で、内側眼窩野の機能を選択的に示したものはほとんどない。眼窩前頭皮質の最前部にある。内側眼窩野を破壊すると、すぐもらえる小さな報酬よりも、あとにもらえる大きな報酬を好むようになる。また、リスクのある選択をするようになる。[9]
内側眼窩野は脱阻止において、報酬の変化に好んで応答する。[10]
外側眼窩野
逆転学習には関与するが、識別学習には関与しない。外側眼窩野を機能抑制すると、あとでもらえる大きな報酬よりも、すぐもらえる小さな報酬を好むようになる。[9]
外側眼窩野の前部はパブロフ的脱報酬価値課題に関与するが逆転学習には関与しない。それに対して外側眼窩野の後部はその両方に関与する。[11]
眼窩前頭皮質の一部もしくは全体の破壊・機能抑制によって遂行障害が出る課題一覧
逆転学習:reversal learning[12]
遅延変更課題:delayed alteration[13]
消去学習:extinction learning[14]
脱報酬価値課題:reinforcer devaluation[15]
感覚事前調整:sensory preconditioning[2]
成果特異的PIT:outcome specific pavlovian-instrumental transfer[16]
過剰期待:over expectaition[17]
時間割引:delay discounting[9]
報酬内容の変更による脱阻止:Unblocking by reward identity change[18]
決定後賭博課題:postdecision wagering task[19]
三段階課題ステート実験:3 stage ''task state'' experiment[20]
サルにおける断線実験
断線(disconnection)
非対称性断線による行動変化を紹介する。
眼窩前頭皮質ー扁桃体(OFC-AMY)
脱報酬価値課題の遂行が障害される。
眼窩前頭皮質ー鼻皮質(OFC-RCX)
報酬規模の違いに対する感度が低下する。
構造
霊長類の眼窩前頭皮質の解剖・組織

眼窩回 の位置を様々な角度から見たアニメーション。赤く塗られているところが眼窩回。
霊長類の眼窩前頭皮質は前頭前野の腹側部の表面にある大きな皮質領域であり、眼窩の直上にある。(これが名称の由来である。)そして、大脳半球の間の壁の一部を含んでいる。解剖学的には、内背側視床の内側大細胞核から軸索投射を受ける前頭前野の一部と定義されており、ブロードマン野の10,11,47からなる。しかしながらブロードマンの初期の分類は終わっておらず、ヒトと非ヒト霊長類では非一貫性を示している。細胞構築に基づく仕事による区分が広く現在受け入れられており、ウォーカー野の10,11,47/12,13,14とされる。前頭前野は一般的に六層構造からなるが、霊長類の眼窩前頭皮質では、五層構造でできている無顆粒性(第Ⅳ層がない)の場所と、六層構造でできている顆粒性(第Ⅳ層がある)の場所が混在している。このことは、他の前頭葉領域よりも眼窩前頭皮質の方が系統発生学的に古いことを提案しており、眼窩前頭皮質が全体に渡って五層構造である非霊長類と霊長類の比較を難しくしている。この違いに基づいて、ワイズらは非霊長類の哺乳類と霊長類の眼窩前頭皮質は相同的な部分を持たないと提案した。この話題についての様々な反対意見が現在進行中である。

他の特筆すべき眼窩前頭皮質の解剖学上の特徴は、解剖学的な''つながり''である。眼窩前頭皮質はすべての感覚野と2シナプスや3シナプスで非常に強くつながっており、さらに、他の前頭葉領域や線条体、扁桃体、海馬などにも広くつながっている。これらの領域に対するつながりのパターンは眼窩前頭皮質における内側ネットワークと外側ネットワークで異なっており、機能的にも内側ネットワークと外側ネットワークが異なっていることを提案する。特に、外側ネットワークは扁桃体や外側眼窩野へ出力しており、嗅覚、味覚、視覚、体性感覚、内蔵感覚に関連する感覚野からの情報の入力を受けている。それに対して、内側ネットワークは、内側壁(ブロードマン野25,24,32)に出力しており、扁桃体、内背側視床、内側側頭葉のさまざまな場所(海馬、海馬傍回など)、腹側線条体、視床下部、中心灰白質から入力を受けている。
まとめると、眼窩前頭皮質は感覚、学習、記憶に関わる様々な領野とつよくつながっている。眼窩前頭皮質は解剖学的に異なる2つのネットワーク(内側と外側)や、細胞構築的に異なる様々な領域(顆粒性か無顆粒性)を持つということ、溝のつくりに個人差が大きいということから、非常に不均一な脳領野であるといえる。[1]
ラットの眼窩前頭皮質の解剖・組織
ラットの眼窩前頭皮質は嗅脳溝の背側にあり、内側眼窩野(medial orbital area:MO)、腹側眼窩野(ventral orbital area:VO)、腹外側眼窩野(ventrolateral orbital area:VLO)、外側眼窩野(lateral orbital area:LO)、背外側眼窩野(dorsolateral orbital area:DLO)、無顆粒性島野(agranular insular area:AI)の6箇所に区分される。ラットでは前頭前野は全て無顆粒性(第Ⅳ層がない)だが、これらの眼窩前頭皮質領域はサルの眼窩内側前頭前野のおよそ尾側3分の1と相同であると考えられている。なぜならこれらの領域は似た配置や皮質下構造とのつながりを持っているからである。特に内背側視床はサルにおいてもラットにおいても全ての眼窩前頭皮質の部分と相互につながっている。現在では行動学的、神経化学的、電気生理学的性質を説明することや、系統発生学やこれらの領域の個体発生における関係性を研究することで、前頭前野の領域を様々な種にわたって定義するための追加基準か作られている。
近年のサルとラットの解剖学的トレース実験による包括的比較解析は、これらの種間での''解剖学的つながりに基づく相同性の推論''を可能にしている。特に、眼窩前頭皮質と線条体の関係はサルとラットで類似している。ラットの内側眼窩野とサルの内側眼窩前頭皮質はどちらも線条体の腹内側部に投射しているし、ラットの外側眼窩野とサルの中心外側眼窩前頭皮質はどちらも線条体の中心部と外側部に投射している。興味深いことに、線条体の投射先領域で分類すれば、腹側眼窩野と外側眼窩野同士は、腹側眼窩野と内側眼窩野よりも近い関係にあり、同等視されたラットの腹側眼窩野と外側眼窩野は(しばしば腹外側眼窩野にも拡張されるが)サルの中心外側前頭眼窩皮質と相同である。
ハーバーとヴァーツは前頭眼窩皮質領域の全脳的投射先マッピングの結果からラットの内側眼窩野と腹側眼窩野について少し違った結論を出した。彼らによればラットの内側眼窩野と腹側眼窩野は同じ皮質領域(線条体、内背側視床、外側視床下部、海馬のほとんどの領域、黒質、腹側被蓋野)に投射している(内側眼窩野は腹側眼窩野へ、腹側眼窩野は内側眼窩野へ、内側眼窩野と腹側眼窩野はどちらも前帯状回、Prelimbic皮質、Infralimbic皮質へ)。しかしながら、おどろくべき内側眼窩野と腹側眼窩野の違いもあった。内側眼窩野は基底外側扁桃体や中心扁桃体に強く投射しているが、腹側眼窩野はそれよりも弱い。内側眼窩野は腹側眼窩野よりも強く側坐核に投射している。一般的に行って、内側眼窩野は腹側眼窩野よりも辺縁系に広く投射している。面白いことに内側眼窩野と腹側眼窩野のどちらも外側眼窩野にはそれほど強く投射していない。ハーバーとヴァーツらの提案は内側眼窩野と腹側眼窩野は目標指向行動の情動的、認知的統合において重要な役割を共有しいるということだ。[9]
研究
この領域に関するヒトを対象とした研究は、健常者に対する脳機能イメージング研究と、眼窩前頭皮質の一部に損傷を負った患者の神経心理学的研究に集中している。
眼窩前頭皮質の機能に関する最初の情報は、偶然の出来事に単を発している。爆発事故で鉄の棒が、今では有名な鉄道作業員であるフィネアス・ゲージの頭を貫き、前頭前野の腹側部にある前頭眼窩皮質は直接損傷を受けた。彼はその後、認知機能は比較的保たれたものの、自分を制御できなくなった。医師ダマシオの患者エリオットは、眼窩前頭皮質が損傷した後、仕事を辞め、妻と離婚し、売春婦と結婚した。これらのことは、その後の眼窩前頭皮質、もっと一般化して前頭前野に対する考え方に大きな影響を及ぼした。フィネアス・ゲージのような患者や実験的に眼窩前頭皮質を 損傷した動物に基づいて、「眼窩前頭皮質の最も重要な機能は行動抑制、抑制的自己制御、感情制御である」と考えられた。しかし最近の研究では眼窩前頭皮質の機能に対するこのような見方について物申すような結果が出ている。これらの結果によると眼窩前頭皮質はもっと確信的な機能を持っている。[21]
マウスの眼窩前頭皮質の神経細胞の軸索投射

図1:AAV-GFPをC57BL/6Jマウスの外側眼窩野に注入してスライスから取得した軸索走行の画像を3次元化した画像の側面像
アレン脳科学研究所では、全脳的に色素を持ったウイルスベクターを注入し、軸索の走行をトレースする実験が行われている。図1はAAV-GFPをC57BL/6Jマウスの外側眼窩野に注入してスライスから取得した軸索走行の画像を3次元化した画像の側面像である。
眼窩前頭皮質→線条体投射[22]
ホン・ウェイ・ドンらは、眼窩前頭皮質のみならず様々な皮質領野が背側線条体にどのように当社しているかという皮質線条体プロジェクトームを発表している。その中で、眼窩前頭皮質についての記載を紹介する。図2は、背側線条体を11個のコンパートメントに分けたものである。

図2:背側線条体:左から順に吻背側線条体、中間背側線条体、尾背側線条体
外側眼窩野の神経細胞は、中間背側線条体背内側部(CPi.dm)、吻背側線条体中間背側部(CPr.imd)、尾背側線条体背側部(CPc.d)に投射している。
腹外側眼窩野の神経細胞は、中間背側線条体背内側部(CPi.dm)、吻背側線条体中間腹側部(CPr.imv)、尾背側線条体背側部(CPc.d)に投射している。[22]
ステート表現
ステート空間理論
意思決定に関する研究の中心は、次の問いに対して脳がどのように答えるかということを理解することである。「環境のステートを考慮し、どの行動が最善の成果につながるだろうか。」多くの研究はこの質問の後半部分に焦点を当てており、その内容は文字通り、どのように行動を選択し、どのように、予期した成果を学習に表現するのだろうかということである。しかし、この質問の前半部分、すなはち、「どのように意思決定は現在の環境に依存し、動物は何を''環境のステート''と考えるのだろうか。」にはあまり注意が向けられていない。動物を取り巻く環境はしばしば、感覚情報にあふれており、それらの時間的関係も複雑であるため、脳が環境のステートをどのように表現しているかということは意思決定を成功させるために非常に重要である。下において「環境のステート」を正確に定義し、意思決定の過程が必要とする環境のステートの表現がどのようになされるかについて詳しく説明する。そして、意思決定においてこれらの情報を表現することいおいて眼窩前頭皮質が特異的な役割を持っていることを提案する。
棒と荷車の課題
強化学習の計算論的理論は、現在の決定に関連のあるすべての情報を表現することに依存している。このすべての情報は''ステート(状態)''と言われる。このステートは、ただ環境における身体状態の1対1の反映であるだけではなく、むしろ意思決定の瞬間に意思決定を行う動物(エージェント)が、環境についてのどの情報を表現しているのかということの反映である。エージェントの脳は、意思決定や学習を適切に行うために、どのくらい正確に環境を表現すればよいのか。下に述べるように、これは簡単な問ではない。たとえば、強化学習を行うエージェンが、棒と荷車が蝶番でつながっていて、右にも左にも動く棒をどのようにバランスよく保つかを学習しようとすると考える(古典的なベンチマークタスク)。強化学習の観点から、この問題を解決するのに適切な方針は、すぐあとの荷車の状態を予測するのに十分な自全ての情報が現在の状態に含まれている場合のみ、計算できる。この特徴はマルコフ特性として知られ、未来の状態の条件付き確率が、過去の状態によらず、現在の状態と行動によってのみ決定されるということを意味している。棒の問題に関しては、荷車の位置と棒の角度を状態として表現するだけでは不十分である。なぜなら、これらの変数だけでは棒がどちらに動き、荷車がどちらに動くかということを予測できないからである。その代わりに、荷車の速度や、棒と荷車の角度がどのくらいの速度で変化しているのかといった情報が必要である。これらの変数を、現在のステートとして表現したほうが、エージェントはよりよく学習ができるであろう。
ステート表現に関するこれらの要請は、あらたな問題を作る。変数によっては、エージェントが感覚から受ける情報と1対1対応していない。例えば、速度に関する変数を推測するには過去と現在の感覚情報を比較しなくてはいけない。このとき、記憶が必要となる。もしステートが、現在アクセス可能な情報以外の情報を反映することを必要としたとき、また、本当の価値を知るのに不確実性があった場合、そのステートは’’部分的に観察可能’’ということにあなる。つまり、意思決定に必要な全ての情報が、現在の感覚情報に含まれておらず、過去の記憶などの情報も現在の感覚情報とともに利用しなければならない場合、そのステートは部分的に観測可能ということになる。
最後に、現在の感覚入力の全てが意思決定に必要なわけではない。例えば、照明条件下で、感覚情報が変化したとしても方針に関係のないものをステートに組み入れる必要はない。不必要な情報をステートに組み入れてしまうと、違うように見えるけれでも等しいと見なすべきそれぞれの状態の方針を区別して学習する必要性から、学習が遅くなってしまう。これを''次元性の苦悩''と呼ぶ。よって、よいステート表現の方法は、この2つの問題を解決するものである。「必要とされる観測不可能な情報を感覚情報に補填することで、部分的に観察可能な、マルコフ的でない環境を扱うことができ、次元性の苦悩を避けるために感覚情報の中から関係のあるものだけを選別することができること。」である。つまり、意思決定に必要な情報を過去の記憶などと現在の感覚情報から表現し、不必要な情報を取り除くことが必要であるということだ。
棒をバランス良く保つことは非常にレアな行為だが、次元生の苦悩と部分的観測可能性は一般的な問題である。この問題を解決できる脳領野は、エピソード記憶や注意選択過程に関わる脳領野と、感覚皮質とアクセス可能であるべきだ。こうした特徴を持つ脳領野として、純粋に解剖学的観点から眼窩前頭皮質は良い候補である。前頭前野の中で独特にも五感と強くつながっており、海馬や線条体のように記憶や意志決定に関わる脳領野と相互的に繋がっているからだ。加えて長年の研究から、意志決定における眼窩前頭皮質の役割は課題の実行に必要なときに部分的に観測可能な環境のステートを表現することであるといわれる。特に2014年のウィルソンらの論文で、眼窩前頭皮質が破壊されると結果に影響が出る課題においてステートの表現の仕方がどのように変わるかが書かれている。中心的な考えとしては、課題のステート空間は多くの場合部分的に観測可能な情報を含んでおり、眼窩前頭皮質を破壊された動物は必要な観測可能な情報と観測不能な情報の統合が出来ないのではないかということだ。この考えを理論的に検証するためヤエルらは強化学習モデルの枠組みを利用した。眼窩前頭皮質が破壊された動物をシミュレーションするため、同じ感覚情報に関連した全てのステートは、同じステートと認識するように設計し、健康な動物は同じ感覚情報に関連した情報を例えば過去の情報などに基づいて識別できるものとして設計した。この操作は前頭眼窩皮質の障害に影響を受ける課題において、わずかながら確実な、課題の遂行障害を起こした。

顔家課題の流れ図
1つの例が遅延変更課題である。この課題は動物においても人においても前頭眼窩皮質が損傷されると遂行障害を生じることで知られる。この課題では2つの単純な行動(例えばレバーを右か左に引くなど)が報酬につながりうる。特別にこの課題における報酬の提示は前回の選択に影響を受ける。たとえばそれぞれの試行で前回選ばなかった選択をした時だけ報酬がもらえるといった具合である。この課題を解決するためには、2つの行動に対応したステートは、前回の選択という情報を補填されなくてはいけない。外的に利用可能な刺激という観点では全ての試行は同じに見えるが、前回Aを選んだ場合最善の選択はBなのであり、前回Bを選んだ時の最善の選択はAなのである。もしも眼窩前頭皮質の損傷が、見た目が同じでも観測不能な情報に基づいて識別しなければならないステートの識別能力を障害するのであれば、眼窩前頭皮質を損傷した動物はこの課題をステートが1つしかないものとして表現するはずである。眼窩前頭皮質を損傷した動物がこの課題をできなくなることは実験的に示されている。2014年のウィルソンらの論文では、眼窩前頭皮質の損傷の結果として起こる様々な行動の障害は、課題の実行の背景にあるステート空間の障害によって起こると説明している。さらに眼窩前頭皮質の損傷によって起きる腹側被蓋野のドーパミン神経の発火の変化がステート識別の障害の結果として起きるとも説明している。
顔家課題の概念図:色は下図と対応している。

顔家課題の説明をするヤエル・ニブ(撮影:2015/10/14)画面の3Dグラフの点の色と概念図の点の色は対応している。点と点の距離は眼窩前頭皮質のfMRI上の活動の相関の強いほど近く、弱いほど遠くなるようになっている。眼窩前頭皮質のfMRI上の活動の相関と概念上の距離が対応していることを示している。
ヒトおける研究を見ていく中で、ヤエルらは、眼窩前頭皮質の意思決定における役割を調べて自分たちの仮説を証明するため、自分たちの仮説を証明するための課題(顔家課題)を用いた。課題の試行において、参加者は右図のような家と顔が重なった図を与えられ、顔か家どちらかについて、古いか(年を取っているか)新しいか(若いか)を考える。この課題で重要なことは、顔か家どちらを判断するかということと、それが実際に古いか新しいかということを連続して考えなくてはいけないということである。顔か家どちらを判断するかというルールは、前回の試行と現在の思考で新しさが変化した場合、次の試行では反対のカテゴリーを判断し、新しさが変化しなければ、同じカテゴリーのものを判断するというものである。最初は顔から始まる。例は右図のようである。したがってこの課題を実行するには、参加者は現在の試行と前回の試行について考えなくてはいけない。与えられたルールの中でこの課題において参加者は部分的に観測可能な16個のステートからなるステート空間を描かなくてはならない。fMRIの画像を多変数解析の技術することにより、ステートのどの側面が眼窩前頭皮質に表現されているかを調べた。この解析によって、それぞれの試行において、ステートの部分的に観測可能な側面(前回の試行の新しさ、前回の試行のカテゴリーなど)についての情報が眼窩前頭皮質に含まれていたことが分かった。全脳的解析によって、内側眼窩前頭皮質のみが全ての必要な観測不能な情報を持っているということが分かった。また、眼窩前頭皮質からは、2試行前の事象といったような課題の遂行に関係のない情報は読み解くことができなかった。一方で他の脳領野からは、課題の遂行に関係のない情報も読み解くことができてしまった。最後に、1回の試行の情報の誤差固定解析により分かったことは、課題遂行の間違いに先行して眼窩前頭皮質のステート表現が劣化するということだ。これらの結果は、今まで述べてきた眼窩前頭皮質が意思決定においてステート表現を行うという仮説に対して強い支持要素となる。
他のいくつかの研究も同じような結論を導いている。げっ歯類の外側眼窩野の神経細胞の電気活動を記録したノグエリアは、前回の試行から得られる、課題遂行に関係する観測不能な情報が現在の感覚入力と統合されたことを報告した。ヤエルの研究室では参加者が過去の観察の連続から現在のステートを推論しなくてはいけないような課題を使って、眼窩前頭皮質の活動は観測可能な出来事の連続を考慮しなくてはならないような観測不能なステートの事後確率を反映することを明らかにした。ブラッド・フィールドは両側の内側眼窩野の機能抑制が、課題の範囲の観測不能な成果の思い出しや予期が出来なくなることにつながるということを報告した。最後に、スタルネイカーは、成果の規模や内容がことあるごとに逆転する課題をラットに試行させ、観測不能の課題のステートが背内側線条体のアセチルコリン性介在細胞の電気活動から読み解けることを明らかにした。非常に重要なことに、眼窩前頭皮質を破壊するとこの情報は消えてしまう。最後に、これらの結果を統合すると、眼窩前頭皮質は、課題遂行に関係のある情報を組み合わせてステート表現を行い、部分的に観測可能な、あるいはマルコフ的でない環境において効果的な意思決定をすることを促進しているといえる。[1]
三段階課題ステート実験
内側眼窩野がステートを表現しているということを因果的に示した実験が、三段階課題ステート実験である。[20]行動実験としては、顔家課題同様に複雑である。まず、前訓練の段階で、刺激1と報酬1、刺激2と報酬2を連合する。次に、随伴性抑制訓練で、行動1を起こすと、刺激1が提示されるが、報酬は提示されない、行動2を起こすと、刺激2が提示されるが、報酬は提示されない、という訓練をする。ここで''抑制性のステート''を学習する。次に随伴性強化訓練で、行動1を起こすと、刺激1が提示されるとともに報酬1が提示される、行動2を起こすと刺激2が提示されるとともに報酬2が提示される、という訓練をする。ここで''強化性のステート''を学習する。これらの2つのステートを学習した段階で、テストを行う。行動1を行うと、刺激1が提示され、行動2を行っても刺激1が提示される、という条件にして報酬は提示しないとしたときに、行動1と行動2のどちらを多く取るかということを観察する。行動1の場合は、刺激1が提示されるので矛盾はないが、行動2の場合は、刺激2ではなく、刺激1が提示されるため矛盾が生じている。このような場合、ラットはどのような行動をとるのか。内側眼窩野が正常のラットは次のように考えると推測される。行動1をとっても報酬が得られないため、ラットはテストの段階は抑制性のステートであると考える。そうすると、矛盾のない選択をしても、報酬がもらえないとわかっているため、報酬がもらえないという情報をまだ学習していない矛盾のある方の選択をする。その結果、行動1よりも行動2をより多くラットは選択する。しかし、内側眼窩野を損傷したラットはそのようなステートの判断がつかないため、直前に行った随伴性強化訓練の結果に従い、矛盾のないほう(行動1)をより多く選択する。
| 前訓練 | 段階1 随伴性抑制訓練 | 段階2 随伴性強化訓練 | 段階3 テスト |
|---|---|---|---|
| 刺激1→報酬1 刺激2→報酬2 | 行動1→刺激1→(報酬1はなし) 行動2→刺激2→(報酬2はなし) | 行動1→刺激1→報酬1 行動2→刺激2→報酬2 | 行動1→刺激1(矛盾なし) 行動2→刺激1(矛盾あり) |
消去学習
光遺伝学的にハロロドプシンを使って眼窩前頭皮質の神経活動を時間特異的に抑制すると、消去学習が障害される。[14]
眼窩前頭皮質のステート表現には海馬の出力が必要である
強制選択課題において、腹側海馬台の機能を光遺伝学的にNpHR(ハロロドプシン)を使って抑制すると、眼窩前頭皮質のステート表現が異常となった。具体的には、強制選択課題における反応方向(選んだ選択肢)に選択的に発火を示す神経細胞の割合が有意に減少した。
逆転学習とステート表現
ヒトやサル、げっ歯類に使われているもっとも古典的な逆転学習は次のようなものである。まず動物は、2つの視覚刺激、空間的位置を識別できるように訓練する。その2つのうちの片方には毎回報酬が伴い、もう片方には伴わない。パフォーマンスレベルが一定の基準に達し、識別訓練が成功したのちに、2つの刺激に随伴した成果を逆転させ(今まで報酬が伴わなかった方に報酬が伴うようになり、今まで報酬が伴った方に報酬が伴わなくなる。)、動物は再びパフォーマンスレベルが一定に達するまで訓練される。これが、道具的、報酬的逆転学習である。パブロフ的逆転学習もあるし、嫌悪的逆転学習もある。道具的逆転学習は、2つの選択肢のうちどちらかを自ら選択するが、パブロフ的逆転学習では、2つの刺激両方に対する反応行動の時間を見ることで実験を行う。[23]
逆転学習についての重要な仮説は、逆転の前後で、動物が表現するステートが変化するということである。眼窩前頭皮質を破壊された動物は、ステート表現ができないため、逆転の前後のステートの変化を表現できず、2つのステートを同一視してしまうため、逆転学習に時間を要する。この仮説は数理的モデル解析によって支持されている。[13]
逆転学習は眼窩前頭皮質の光遺伝学的機能抑制によっても障害される。ただし、この光遺伝学的操作は時間得意的である。[24]
眼窩前頭皮質と基底外側扁桃体

OFC:眼窩前頭皮質、BLA:基底外側扁桃体、pre-reversal:初期学習、post-reversal:逆転後
初期学習において、眼窩前頭皮質と基底外側扁桃体は、報酬を予期する刺激に応答する。しかし、刺激と報酬の随伴性が逆転したとき、これらの2領野での神経細胞の反応は異なる。基底外側扁桃体は、初期学習において報酬を予期していた刺激に応答していた神経細胞が、逆転後には逆転後に報酬を予期するようになった刺激に応答するようになる。しかしながら、眼窩前頭皮質では約2割の細胞が今までの応答性を逆転させるが、初期学習において刺激選択的でなかった神経細胞集団が、新しい、報酬を予期する刺激に応答するようになる。
眼窩前頭皮質の破壊によって、逆転学習は時間をようするようになるが、さらに基底外側扁桃体を破壊すると、逆転学習は再び素早くできるようになる。
モデルベースの推論
モデルベースの推論とは、経験によって形成された内的モデルに基づいて、直接の経験によらない意思決定を可能にするような推論である。モデルベースの推論に基づく行動課題として次のようなものが挙げられる。
モデルベースの推論に基づく行動課題
①脱報酬価値課題(Reinforcer Devaluation)

罰連合型脱報酬価値課題の図 Light CS:光による条件刺激 LiCl:LiClに腹腔内投与により腹痛を誘発
脱報酬価値課題とは英語で「Reinforcer Devaluation」のことである。脱報酬価値課題は、条件刺激もしくはオペラント行動と連合した報酬(無条件刺激)の価値を低下させることで、条件刺激への反応行動やオペラント行動が減少することを確認する実験である。報酬の価値を低下させる方法は、大きく分けて2つある。一つは報酬と罰を連合させることで、報酬の価値を低下させるというもの。これを罰連合型脱報酬価値課題と名付ける。もう一つは、報酬との連合学習を成立させたのちに、報酬を沢山与えて、報酬に対して飽きさせることで報酬の価値を低下させるというもの。これを飽満型脱報酬価値課題と名付ける。ジェフリー・ショーエンバウムらは、外側前頭眼窩皮質を、条件刺激を提示しているタイミングで光遺伝学的に抑制したところ、罰連合型脱報酬価値課題において、脱報酬価値後の条件刺激への反応行動は、有意に上昇したことを確認した。[15]このころから、前頭眼窩皮質は、「脱報酬価値課題によって報酬価値が低下したのだから、その報酬と連合された条件刺激への反応をやめよう」というモデルベースの推論を行っていると考えられる。
| 条件付け | 脱報酬価値 | 試験 |
| 刺激→報酬 | 報酬→LiCl | 刺激→? |
※LiCl:LiClの腹腔内投与により腹痛を誘発

外側眼窩野のパルブアルブミン陽性細胞の神経活動を活性化し、投射神経を抑制した実験の図
クリスティーナ・グレメルらは、飽満型脱報酬価値課題を行った。グレメルらが行った脱報酬価値課題について詳しく述べる。まず、マウスは、レバーを押せば砂糖水を得られるということを学習する。この段階を訓練段階と呼ぶ。次に、マウスに砂糖水をたくさん与えて、飽きさせる。この段階を再暴露段階と呼ぶ。再暴露において砂糖水をなめた瞬間の外側眼窩野の活動を光遺伝学的に抑制したところ、抑制していないマウスに比べて、再暴露後のレバー押しが多く見られた。すなわち、再暴露中の砂糖水をなめた瞬間の外側眼窩野の活動は、報酬を低下させる、報酬の価値をアップデートするのに必要であるということを意味している。[25]
②感覚事前調整(Sensory Preconditioning)

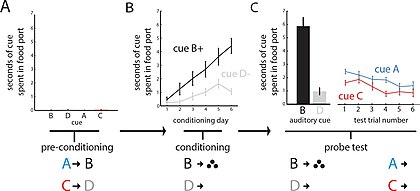
感覚事前調整の図
感覚事前調整とは英語で「Sensory Preconditioning」のことである。感覚事前調整では条件刺激を2つ用いる。刺激1と刺激2を同時にラットに提示する。次に、刺激2を提示した状態で報酬を与える。次に刺激1を提示すると、報酬がなくても、刺激1に対して反応行動を示すようになる。刺激1に対する反応行動を見る段階で、薬理学的に眼窩前頭皮質を抑制すると、刺激1に対する反応行動は、抑制していないラットに比べて有意に減少する。このことから眼窩前頭皮質は「報酬と連合しが刺激2と関連する刺激1が提示されているならば報酬も提示されるであろう」というモデルベースの推論を行っていると考えられる。[2]
| 事前調整 | 条件付け | 試験 |
| 刺激1→刺激2 | 刺激2→報酬 | 刺激1→? |
感覚事前調整に関するジェフリー・ショーエンバウムらの実験を説明しよう。右に、本実験の行動試験の概要を示す。まず図Aについて、刺激Aを提示したのに続けて刺激Bを提示する。また、刺激Cを提示したのに続けて刺激Dを提示する。この訓練を繰り返し行う。この訓練中に報酬は提示されないので、刺激に対する報酬的な反応行動は見られない。次に図Bについて、刺激Bと報酬をペアにして提示すると、刺激Bに対して報酬的な反応行動が見られるようになる。また、刺激Dを単独て提示する。次に図Cについて刺激Bと刺激Dに対する報酬的な反応行動の割合を比較すると刺激Bに対する反応の方が優位に高い。
事前調整の段階で、眼窩前頭皮質の神経細胞266個の神経活動を記録したところ、112個の細胞で少なくとも1つの刺激に対して神経活動が上昇した。そのうち45個は、AとBどちらにも反応する、あるいはCとDどちらにも反応するという神経細胞だった。
③報酬内容の変更による脱阻止(Unblocking by reward identity change)[18]
まず阻止(ブロッキング)という現象について説明する。刺激1に続いて報酬1を提示する。これを訓練して刺激1に対して反応行動を起こすようになる。次に、刺激1と刺激2を同時に提示して、続いて報酬1を提示する。これを訓練する。試験において刺激2を提示して反応行動が現れるかを確認する。報酬学習は刺激が予測誤差を生じた場合に、その誤差が駆動力となって成立する。刺激1と刺激2を同時に提示して、報酬1を提示した場合、報酬が刺激1によって完全に予測されているためにこの訓練課程では予測誤差が生じていないので刺激2に対しては反応行動が獲得されない。これは刺激1が刺激2の報酬学習を阻止したといえるのでこの現象を阻止(ブロッキング)という。次に、報酬内容の変更による脱阻止について説明する。刺激1に続いて報酬1を提示する。次に、刺激1と刺激2を同時に提示し、続いて報酬2を提示する。この場合、刺激2によって報酬内容が変更されたと訓練動物は認識し、報酬内容に関する予測誤差が生じるので刺激2に対して反応行動が獲得される。これを、報酬内容の変更による脱阻止という。
| 初期学習 | 複合学習 | 試験 |
| 刺激1→報酬1 | 刺激1+刺激2→報酬2 | 刺激2→? |
④PIT(Pavlovian-Instrumental Transfer)
古典的条件付けと道具的条件付けを続けて行い、試験の段階で、道具的条件付けの時に獲得した行動が古典的条件付けした刺激に対して増加する。
これを見るテストをPITという。PITの中でも、古典的条件付けのときに用いる報酬と、道具的条件付けのときに用いる報酬が同じ場合を成果特異的PITと呼ぶ。成果特異的PITは眼窩前頭皮質の損傷によって障害される。[26]
| 古典的条件付け | 道具的条件付け | PIT試験 |
| 刺激→報酬A | 行動→報酬AorB | 刺激→? |
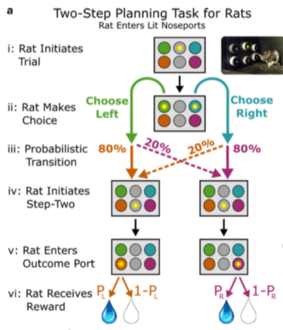
⑤マルコフの2ステップ課題ラット版
マルコフの2ステップ課題ラット版では、成果期と選択期が存在する。成果期に報酬学習が行われるわけだが、眼窩前頭皮質を時間特異的に成果期でだけ抑制すると、モデルベースの推論ができなくなった。選択期に抑制してもモデルベースの推論はできなくならない。[27]
⑥過剰期待
条件付けにおいて、刺激1と報酬(1)、刺激2と報酬(1)を連合する。次に、複合訓練で刺激1と刺激2を同時に提示したとき、報酬(1)を提示する。このとき、ラットは、報酬(2)を期待するが、報酬(1)しか提示されないため、負の予測誤差が生じ、刺激1、刺激2と報酬についてお互いの連合を弱めてしまう。その結果、刺激2に対する反応行動の時間が、複合訓練をしない場合に比して、短くなる。眼窩前頭皮質の細胞発火を複合訓練のタイミングで抑制すると、この効果はなくなる。[28]
| 条件付け | 複合訓練 | 試験 |
| 刺激1→報酬(1)、刺激2→報酬(1) | 刺激1+刺激2→報酬(1) | 刺激2→? |
※( )の中の数字は報酬の規模
海馬-眼窩前頭皮質-腹側被蓋野(Hip-OFC-VTA)によるモデルベースの推論
海馬ー眼窩前頭皮質ー腹側被蓋野はそれぞれモデルベースの推論に必要な脳領野であることが示されているが、それぞれの脳領野の協調的機能については不明な点が多い。ここではそれぞれの脳領野の、個別のモデルベースの推論における機能と、協調的な機能について説明する。
背側海馬(dorsal Hippocampus:dH)
背側海馬はモデルベースの推論に寄与する脳領野である。カルロス・ブロディーらは、マルコフの2ステップ課題のラット版において、海馬をムッシモールで抑制し、行動を解析したところ、モデルベースの推論ができなくなっていることを発見した。[29]
眼窩前頭皮質(Orbitofrontal Cortex:OFC)

眼窩前頭皮質はモデルベースの推論に寄与する脳領野である。カルロス・ブロディーらは、マルコフの2ステップ課題のラット版において、学習のタイミングで眼窩前頭皮質を光遺伝学的に抑制し、行動を解析したところ、モデルベースの推論ができなくなっていることを発見した。
[27]
腹側被蓋野(ventral tegmental area:VTA)

腹側被蓋野ドーパミン神経の発火頻度 T1 trial:非推論的試行、Inference trial:推論的試行、Control:正常ラット、OFCx:眼窩前頭皮質機能破壊ラット、正常ラットでは非推論的試行と推論的試行で予測誤差の表示に差が出ているが、眼窩前頭皮質破壊ラットではその差がなくなっている。
腹側被蓋野のドーパミン神経はモデルベースの推論に重要である。ジェフリー・ショーエンバウムらは、ドーパミン神経を光遺伝学的に時間特異的に制御することで、報酬内容の変更による脱阻止[30]や感情事前調整を障害する実験を行った。[31]
腹側被蓋野のドーパミン神経は、成果の報酬を推測し、予測誤差を発火頻度として表現することができる。予測誤差を示す発火は、推論を行って予測誤差を減らすことで、減らすことが出来る。実際に、予測誤差を生じさせるような行動課題において、推論できるような試行を用いると、そうでない試行に比して、ドーパミン神経の予測誤差の表示は小さくなる。さらに、この推論による予測誤差表示の変化は、眼窩前頭皮質の破壊によって見られなくなることが分かった。このことはドーパミン神経の予測誤差における推論の影響が、眼窩前頭皮質に依存して出るということを示している。[32]
価値情報の表現
報酬価値のシグナルとその意思決定における役割
眼窩前頭皮質は与えられた選択肢に関連した経済的価値を、経験だけに頼らず臨機応変に表現している。この理論は餌を選んでいる時の、サルの眼窩前頭皮質の電気記録によって得られた。ポダ・シッポアとアサドは2種類のジュースの中から1つを選んでいる時のサルの眼窩前頭皮質からの電気活動を記録した。それぞれの試行において、それぞれのジュースの量が画面の表示によってサルに伝えられる。そしてサルはどちらの選択肢を選ぶか自由に選べる。標準的な経済理論に則り、サルの選択から、それぞれのジュースの主観的価値を計算した。そして、眼窩前頭皮質の神経細胞の発火が何を選択したかにかかわらず線形的変化(いくつかのものは上昇し、いくつかのものは低下する)するものの割合を、選択したジュースとともに示した。価値の表現は、選択の運動的側面と感覚的側面とは独立している。[1]
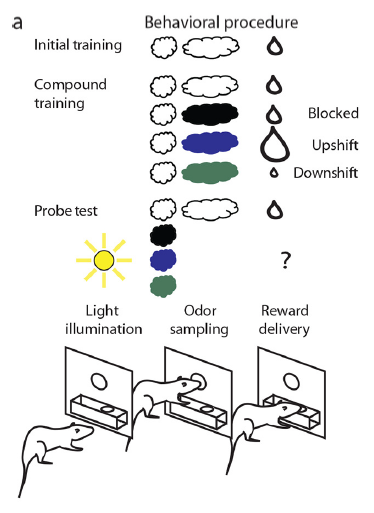
眼窩前頭皮質の神経細胞の電気活動
眼窩前頭皮質は、行動をガイドするために、予期される結果に対する報酬価値を表現することができる。この報酬価値の表現の仕組みを知るために行ったジェフリー・ショーエンバウムらの仕事を紹介しよう。まず初期学習において、刺激1と報酬(中)を連合する。次に、複合学習において、刺激1+刺激2と報酬(中)、刺激1+刺激3と報酬(大)、刺激1+刺激4と報酬(小)を連合する。このようにすると、刺激2に対する反応行動は、複合学習において刺激1がなかった場合と比較すると減少する。なぜならば、初期学習の結果、刺激1の提示でラットは報酬(中)を予期するようになったため、複合学習においても報酬(中)を予期してしまう。その状態で刺激2が提示されると、予測誤差が生じないために、刺激2と報酬(中)の連合は起きない。これを阻止(ブロッキング)という。刺激1が刺激2と報酬の連合を阻止したということである。刺激3に対する反応行動は、刺激2に対するものに比して大きくなる。なぜならば、複合学習において刺激1は報酬(中)を予期するが、刺激3が伴ったことで報酬(大)が提示されたため、報酬(大マイナス中)分の予測誤差が生じ、この予測誤差が、刺激3と報酬の連合を促進する。これを脱阻止(アンブロッキング)と呼ぶことにする。刺激4に対する反応行動は、刺激2に対するに対するものに比して小さくなる。なぜなら、複合学習において、刺激1は報酬(中)を予期するが、刺激4が伴ったことで報酬(小)が提示されたため、報酬(小マイナス中)分の負の予測誤差が生じ、これが刺激4と報酬の連合を負に制御することになる。さて、阻止された刺激2、報酬が上昇した刺激3、報酬が減少した刺激4に対する眼窩前頭皮質の細胞の応答はどのようになるのか。外側眼窩前頭皮質のニューロン680個のうち、少なくとも1つの刺激に応答するがすべての刺激に同様には応答しない細胞が、120個見つかった。そのなかで、上昇した刺激に対して顕著に応答した60個の細胞についてよく調べてみると、上昇した刺激に特異的に応答した細胞は19個、報酬に予期的に応答した細胞は16個、刺激2,3,4、すなはち複合学習における新しい刺激に応答した細胞が10個、報酬価値に応じて反応した細胞が5個、解釈不能なものが10個であった。[33]
| 細胞の表現する情報 | 上昇した刺激 | 報酬予期 | 新奇性 | 報酬価値 | 解釈不能 |
|---|---|---|---|---|---|
| 細胞の数 | 19 | 16 | 10 | 5 | 10 |
眼窩前頭皮質の神経細胞が表現している情報一覧
報酬の規模(量)[34]
報酬を得るのに必要な努力[34]
報酬を得られる確率[34]
報酬の顕著性(サリエンス)[35]
新奇性[33]
予期報酬の変化[33]
新しい研究結果によると、前頭眼窩皮質の最も重要な機能は、望まれない行動を抑制し感情を制御するというよりも、むしろ感覚事象や行動選択に続いて起こる結果を予測し、これらの成果の評価をアップデートすることである。これらのシグナルは選択の瞬間において重要な役割を果たす。サルの研究結果から、眼窩前頭皮質は、抽象的な共通通貨の形で、目標としての対象の価値を表現していることが分かった。しかし、げっ歯類の研究結果では、眼窩前頭皮質は共通通貨のような形で一般的に成果を表現しているというよりも、むしろ特異的に成果を表現していると分かった。これらのことから眼窩前頭皮質は、条件刺激や強化子と関連した、手に入る成果の感覚的質を表現していると考えられる。哺乳類の間での眼窩前頭皮質の違いを研究することはいまだに行われているが、全ての哺乳類の前頭眼窩皮質について言えることは、将来の行動の成果を、報酬的な意味でも嫌悪的な意味でも予期するのに大切であるということだ。[21]
ラットにおける眼窩前頭皮質と他領野との相互作用
海馬と眼窩前頭皮質(Hip-OFC)連関[36]

左:正常ラットの眼窩前頭皮質の神経細胞の課題遂行中の活動 右;海馬の出力を抑制したラットの眼窩前頭皮質の神経細胞の課題遂行中の活動
海馬と眼窩前頭皮質はどちらも、学習や記憶、意思決定のような認知過程に重要である。しかしながら、この2領野は独立的に調べられてきた。この2領野は似ている点が多く、並行的でありながらも、相互作用しながら認知地図(Cognitive Map)を表現している。
独自の解剖学的、電気生理学的、生化学的特徴を持っていながら、海馬と眼窩前頭皮質はよく似た機能を持っている。たとえば、眼窩前頭皮質の中心的な機能は「感覚事象や行動選択に続く特異的な結果を予期する」ことであるといわれるが、海馬の機能は「これから起こる事象の予期を促進する」といわれる。これらの表現はとても一般化された機能について説明しているが、とてもこの2領野がよく似ていることを示している。これらの構造は、柔軟な行動できるように将来を予測したり、環境についての知識を一般化したりするのに役立つ。海馬と眼窩前頭皮質は相互作用し、認知地図の形成と行動出力に寄与する。

腹側海馬の出力を抑制すると、眼窩前頭皮質のタスクの表現が正常にできなくなるということが、ジェフリー・ショーエンバームらの実験で分かった。匂いガイド下意思決定課題におけるOFCの神経活動を記録した。報酬予期の時間に最も発火頻度が上昇した細胞の割合を測定したところ、腹側海馬を抑制したラットと抑制していないラットでは抑制したラットの方が割合が少なかった。[36]
基底外側扁桃体-眼窩前頭皮質(BLA-OFC)連関[37]
基底外側扁桃体から眼窩前頭皮質に投射する神経細胞をDREADDで薬理遺伝学的に抑制すると、PITができなくなることが証明された。
眼窩前頭皮質を機能抑制すると逆転学習が障害されるが、その影響は、基底外側扁桃体を機能抑制すると無くなってしまう。
つまり、眼窩前頭皮質と基底外側扁桃体をどちらも機能抑制すると、逆転学習は障害されなくなる。
眼窩前頭皮質と腹側線条体(OFC-VS)連関[38]
眼窩前頭皮質を破壊すると、腹側線条体の神経細胞の中で報酬規模特異的に応答する細胞の数が減り、報酬内容特異的に応答する細胞の数が増える。
眼窩前頭皮質-腹側被蓋野(OFC-VTA)連関[39]
眼窩前頭皮質を破壊すると、古典的条件付けにおける 腹側被蓋野 のドーパミンニューロンの条件刺激に対する発火頻度の上昇度合いが低下し、報酬排除による発火頻度の減少度合いが低下する。[40]
腹側被蓋野のドーパミン神経は眼窩前頭皮質と同様にモデルベースの推論に重要な機能を果たす感覚事前調整や報酬内容の変更による脱阻止といったモデルベースの推論課題は眼窩前頭皮質の機能抑制により遂行障害が起きるが腹、被蓋野のドーパミン神経を抑制しても、同様に機能障害が起きる。また、眼窩前頭皮質は腹側被害蓋間接的にシグナルを送っている。眼窩前頭皮質を電極で電流刺激すると、腹側被蓋野のドーパミン神経の発火パターンは変化する(主に抑制される)。これは眼窩前頭皮質が腹側被蓋野のドーパミン神経を介してモデルベースの推論を行っているということを示唆している(これは、筆者の推論であり、実験的に証明されたものではない)。眼窩前頭皮質は腹側線条体と背側線条体に強く投射しており、腹側線条体と背側線条体は腹側被蓋野に強く投射している。
眼窩前頭皮質-二次運動野[41]

眼窩前頭皮質から2次運動野に投射する神経細胞を特異的にDREADDで機能抑制した実験の概念図
眼窩前頭皮質から二次運動野に投射する神経をDREADDで抑制すると、より探索的な行動を取るようになり、搾取的でなくなる。探索(exploration)と、搾取(exploitation)について少し説明する。探索と搾取は心理行動科学的には対義語である。搾取とはこれまでに報酬との関連を学習した刺激や行動を好んで選択して、報酬との関連がないような刺激や行動はとらないという傾向である。それに対して探索とは、これまで報酬との関連がないような刺激や行動に興味をもって、そのようなものを選択していく傾向である。たとえば、おいしい料理店があったとして、ここにいけば美味しいご飯が食べられると分かっているのでいつもここに行く。他の店はおいしくないかもしれないからいかない、というのが搾取的である。それに対して、ほかの店にもいってみよう、というのが探索的である。レバー1と報酬との関連を学習させた後に、試験でレバー2(報酬とは無関係)を提示したときレバー1とレバー2のどちらを多く押すかという実験で、コントロール群に比較して、DREADD群では、レバー2よりレバー1を好む性質、すなわち搾取性が低下しており、探索性が上昇していた。[41]
潜在的原因表現
眼窩前頭皮質は、状況の表現(State Representation)、潜在的原因(Latent Cause)の表現に重要であることがヤエル・ニブらの研究で分かった。状況の表現は、眼窩前頭皮質における認知地図(Cognitive Map)の表現を可能にしている。ステート表現とは、意思決定に必要な環境の情報を表現することであるが、ヒトのfMRIの実験から、意思決定に必要なタスクの状況の情報を前頭眼窩皮質が持っていることが証明された。潜在原因は目の前の状況を作り出す潜在的な、直接観測不能な原因のことである。この情報も眼窩前頭皮質が持っていることが証明された。
患者に対する神経心理学的研究
ロールズ (Rolls) らは、逆転学習 (reversal learning) と消去 (extinction) の2種類の視覚弁別課題 (visual discrimination test)[42]を行った。まず、逆転学習では実験参加者に A と B の2つの写真を見せ、写真 A が呈示された時にボタンを押すと報酬を得ることが出来、写真 B が呈示されている時にボタンを押すと罰が与えられることを学ばせる。この課題では、このルールの学習が終わった後にルールが入れ替えられる。つまり、写真 B が呈示されている時にボタンを押せば正解となるようにする。ほとんどの健常者は即座にルールの逆転に気づくことが出来るが、眼窩前頭皮質に障害を負った患者は、罰を与えられるにもかかわらず、一度強化された元々のパターンに反応し続けてしまう。ロールズ (Rolls) らは、この行動パターンは被験者らがルールの逆転を理解したと報告している点で、特に不可解であると述べている。
2つめの課題として消去に関する課題を行った。この課題では、もう一度実験参加者に写真 B ではなく写真 A に対してボタンを押すように学習させる。しかし、今回はルールを逆転させるかわりに、ルールをまったく変えてしまう。今回はどちらの写真に対してボタンを押しても罰が与えられるようにしてしまうのだ。この課題に対する正しい選択はボタンをまったく押さないことである。しかし、眼窩前頭皮質の機能障害をもった患者は、それを行えば罰せられるにもかかわらず、ボタンを押したいという誘惑に逆らえない。
アイオワ・ギャンブリング課題 (Iowa gambling task) と呼ばれる、現実世界の意思決定を模倣した認知や情動の研究に広く使われる課題がある[43]。実験参加者にはコンピュータ画面に4つの仮想的なカードのデッキが呈示される。彼らは毎回カードを選び、その裏に書かれた分のゲーム通貨を得る、または失う。この課題の目的は、出来るだけ多くのお金を得ることであり、参加者には意識的に考えながらではなく"直感"に従ってカードを選んでもらう。デッキの内の2つは"悪いデッキ"となっていて、長期的に見れば収支はマイナスになる。残りの2つのデッキは"良いデッキ"になっていて、長期的に見れば収支はプラスになる。多くの健常者は約40から50試行後には"良いデッキ"を選び続けるようになる。しかし、眼窩前頭皮質の機能障害を持った患者の場合、その選択が最終的に損であると分かっている場合も存在するにもかかわらず、"悪いデッキ"に保続 (Perseveration) し続ける。同時に行った電気皮膚反応 (galvanic skin response) の計測では、健常者が"悪いデッキ"を選択しようとする際のストレス反応は、たった10試行後という、意識的な"悪いデッキ"の判断が生じるはるか以前から計測される。しかしこの結果とは対照的に、眼窩前頭皮質の機能障害を持った患者では、この差し迫った罰に対する生理的な反応が観測されることはない。この実験を行ったベシャラ (Bechara) らは、このことをソマティック・マーカー仮説 (somatic markers hypothesis) の観点から説明している。アイオワ・ギャンブリング課題は現在、精神医学や神経学などの多くの研究に用いられていて、統合失調症や強迫性障害などの患者や健常者において、この課題を行っている際にどの脳領域が活動するかがfMRIを用いて調べられている。
社会的失言検出課題 (Faux pas test) は誰かが不適切な発言をした際の社会的状況を用いた課題である。参加者が行う課題は、どの発言が不適切なのか?、なぜその発言が不適切なのか?、その社会的失言に対して人々がどのような反応をするか?、そして対照群として、この状況の事実に関する質問に答えることである。元々は自閉症スペクトラムのある人々のために作られたものだった[44]が、この課題は眼窩前頭皮質の機能障害を持ち、物語は完全に理解できるものの社会的に不適切な出来事を判断できなくなった患者に対しても検出力を示す。
著名な眼窩前頭皮質の研究者
Geoffrey Schoenbaum (NIH,メリーランド大学、ジョンス・ホプキンス大学)
Yael Niv (プリンストン大学)
Elisabeth A. Murray (NIH)
Camillo Padoa-Schioppa (ワシントン大学)
Samuel J Gershman (ハーバード大学)
Barry J. Richmond (NIH)
David Redish (ミネソタ大学)
Adam Kepecs (コールド・スプリング・ハーバー研究所)
Jonathan Wallis (タスマニア大学)
Carlos Brody (プリンストン大学、ハワード・ヒューズ医学研究所)
Christina M. Gremel(カリフォルニア大学サンディエゴ校)
関連項目
- フィネアス・ゲージ
- ハワード・ヒューズ
- 強迫性障害
出典
- ^ abcdeNicolas W. Schuck, Robert C. Wilson, Yael Niv A State Representation for Reinforcement Learning and Decision-making in the Orbitofrontal Cortex. bioRXiv (2017)
- ^ abcAndrew M. Wikenheiser and Geoffrey Schoenbaum Over the river, through the woodscognitive maps in the hippocampus and orbitofrontal cortex. Nature Reviews Neuroscience (2016)
^ Lopatina N1, Sadacca BF1, McDannald MA2, Styer CV1, Peterson JF1, Cheer JF3, Schoenbaum G1 Ensembles in medial and lateral orbitofrontal cortex construct cognitive maps emphasizing different features of the behavioral landscape. APA PsycNET (2017)
- ^ abKringelbach, M. L. (2005) "The orbitofrontal cortex: linking reward to hedonic experience." Nature Reviews Neuroscience 6: 691-702.
^ Bechara, A.; Damasio, A. R.; Damasio H. & Anderson, S.W. (1994) "Insensitivity to future consequences following damage to human prefrontal cortex". Cognition 50: 7-15.
^ Snowden, J. S.; Bathgate, D.; Varma, A.; Blackshaw, A.; Gibbons, Z. C. & Neary. D. (2001) "Distinct behavioural profiles in frontotemporal dementia and semantic dementia". J Neurol Neurosurg Psychiatry 70: 323-332.
^ J. Wilson, M. Jenkinson, I. E. T. de Araujo, Morten L. Kringelbach, E. T. Rolls, & Peter Jezzard (October 2002). “Fast, fully automated global and local magnetic field optimization for fMRI of the human brain”. NeuroImage 17 (2): 967–976. doi:10.1016/S1053-8119(02)91172-9. PMID 12377170.
^ Kringelbach, M. L. and Rolls, E. T. (2004). “The functional neuroanatomy of the human orbitofrontal cortex: evidence from neuroimaging and neuropsychology”. Progress in Neurobiology 72: 341–372. doi:10.1016/j.pneurobio.2004.03.006.
- ^ abcdeAlicia Izquierdo Functional Heterogeneity within Rat Orbitofrontal Cortex in Reward Learning and Decision Making Journal of Neuroscience (2017)
^ Geoffrey Schoenbaum et al. Medial Orbitofrontal Neurons Preferentially Signal Cues
Predicting Changes in Reward during Unblocking (Journal of Neuroscience (2016)
^ Marios C. Panayi, Simon Killcross (2018). “Functional heterogeneity within the rodent lateral orbitofrontal cortex dissociates outcome devaluation and reversal learning deficits”. eLife.
^ Geoffrey Schoenbaum et al.Orbitofrontal inactivation impairs reversal of Pavlovian learning by interfering with disinhibition of responding for previously unrewarded cues. Eur J Neuroscience (2009)
- ^ abYael Niv et al. Orbitofrontal Cortex as a Cognitive Map of Task Space Neuron (2014)
- ^ abGeoffrey Shoenbaum et al. Neural Estimates of Imagined Outcomes
in the Orbitofrontal Cortex Drive Behavior and Learning Neuron (2013)
- ^ abGeoffrey Schoenbaum et al. Lateral Orbitofrontal Inactivation Dissociates Devaluation-Sensitive Behavior and Economic Choice. Neuron (2017)
^ Bernardo Balleine et al. The orbitofrontal cortex, predicted value, and choice. Ann N Y Acad Sci. (2011)
^ Thinking Outside the Box: Orbitofrontal Cortex, Imagination,
and How We Can Treat Addiction (Geoffrey Schoenbaum et al. Neuropsycopharmacology 2016)
- ^ abGeoffrey Schoenbaum et al. Ventral Striatum and Orbitofrontal Cortex Are Both
Required for Model-Based, But Not Model-Free,
Reinforcement Learning Journal of Neuroscience (2011)
^ Adam Kepecs et al. Orbitofrontal Cortex Is Required for Optimal Waiting Based on Decision Confidence. Neuron (2014)
- ^ abBernard Balleine et al. Medial Orbitofrontal Cortex Mediates Outcome Retrieval in Partially Observable Task Situations Neuron (2015)
- ^ abElisabeth Murray et al. The Orbitofrontal Oracle:Cotical Mechanism for the Prediction and Evaluation of Specific Behavioral Outcomes Neuron (2014)
- ^ abHouri Hintiryan, Nicholas N Foster, Ian Bowman, Maxwell Bay, Monica Y Song, Lin Gou, Seita Yamashita, Michael S Bienkowski, Brian Zingg, Muye Zhu, X William Yang, Jean C Shih, Arthur W Toga & Hong-Wei Dong (2016). “The mouse cortico-striatal projectome”. Nature Neuroscience.
^ AND A. HOLMES et al. THE NEURAL BASIS OF REVERSAL LEARNING: AN UPDATED PERSPECTIVE Neuroscience (2017)
^ 小川 正晃 報酬に基づく意思決定を司る神経回路機能の解明 上原記念生命科学財団研究報告集, 29 (2015)
^ Emily T Baltz, Ege A Yalcinbas, Rafael Renteria, Christina M Gremel (2018). “Orbital frontal cortex updates state-induced value change for decision-making”. eLIFE.
^ Sean B. Ostlundand, Bernard W.Balleine Orbitofrontal Cortex Mediates Outcome Encoding in Pavlovian But Not Instrumental Conditioning Journal of Neuroscience (2007)
- ^ abCarlos Brody et al. Value Representations in Orbitofrontal Cortex Drive Learning, but not Choice. bioRXiv (2018)
^ Thinking Outside the Box: Orbitofrontal Cortex, Imagination, and How We Can Treat Addiction (Geoffrey Schoenbaum et al. Neuropsycopharmacology 2016)
^ Carlos Brody et al. Dorsal hippocampus contributes to model-based planning Nature Neuroscience (2017)
^ Geoffrey Schoenbaum et al. Optogenetic Blockade of Dopamine Transients Prevents Learning Induced by Changes in Reward Features. Current Biology (2017)
^ Geoffrey Schoenbaum et al. Dopamine transients are sufficient and necessary for acquisition of model-based associations Nature Neuroscience (2017)
^ Geoffrey Schoenbaum et al. Effects of inference on dopaminergic prediction errors depend on orbitofrontal processing. Behavior Neuroscience (2017)
- ^ abcGeoffrey Shoenbaum et al. Lateral orbitofrontal neurons acquire responses to upshifted, downshifted, or blocked cues during unblocking. eLife (2015)
- ^ abcJonathan D. Wallis et al. Double dissociation of value computations in orbitofrontal and anterior cingulate neurons. Nature Neuroscience (2017)
^ Geoffrey Schoenbaum et al. Risk-Responsive Orbitofrontal Neurons Track Acquired Salience. Neuron (2013)
- ^ abGeoffrey Schoenbaum et al, Supression of Ventral Hippocampus Output impairs Integrated Orbitofrontal Encoding of Task. Structure Neuron (2017)
^ Kate Wassum et al. Basolateral Amygdala to Orbitofrontal Cortex Projections Enable Cue-Triggered Reward Expectations Journal of Neuroscience (2017)
^ Geoffrey Schoenbaum et al. Orbitofrontal lesions eliminate signalling of biological significance in cue-responsive ventral striatal neurons. Nature Communications (2017)
^ Geoffrey Schoenbaum et al. Expectancy-related changes in firing of dopamine neurons depend on orbitofrontal cortex Nature Neuroscience (2011)
^ Geoffrey Schoenbaum et al. Expectancy-related changes in firing of dopamine neurons depend on orbitofrontal cortex Nature Neuroscience (2011)
- ^ abDrew C. Schreiner & Christina M. Gremel (2018). “Orbital Frontal Cortex Projections to Secondary Motor Cortex Mediate Exploitation of Learned Rules”. Scientific Report.
^ Rolls, E. T.; Hornak, J.; Wade, D. & McGrath, J. (1994) "Emotion-related learning in patients with social and emotional changes associated with frontal lobe damage." J Neurol Neurosurg Psychiatry 57: 1518-1524.
^ Bechara, A.; Damasio, A. R.; Damasio H. & Anderson, S.W. (1994) "Insensitivity to future consequences following damage to human prefrontal cortex". Cognition 50: 7-15.
^ Stone, V.E.; Baron-Cohen, S. & Knight, R. T. (1998a) "Frontal Lobe Contributions to Theory of Mind." Journal of Medical Investigation 10: 640-656.
外部リンク
前頭眼窩野 - 脳科学辞典
- 科学雑誌Cerebral Cortex の眼窩前頭皮質の特集
大脳の脳回 | ||
|---|---|---|
| 外側面 | 外側溝内部 | 内側面 - 上部 |
 上前頭回 中前頭回 弁蓋部 + 三角部 + 眼窩部 ll 下前頭回 中心前回 中心後回 上頭頂小葉 下頭頂小葉 ll 縁上回 + 角回 後頭回 上側頭回 中側頭回 下側頭回 |  島回 横側頭回 |  舌状回 楔部 楔前部 中心傍小葉 帯状回 (前部+後部) 上前頭回 脳梁 梁下野 梁下回 |
| 脳底部 - 眼窩面 | 脳底部 - 側頭葉下面 | 内側面 - 下部 |
 眼窩回 直回 嗅球 |  鉤 下側頭回 紡錘状回 海馬傍回 |  歯状回 紡錘状回 鉤 海馬傍回 |
| ||||||||||||||||||||


